
Znáš to – je pátek pozdě odpoledne, od volného víkendu tě dělí vydán�í poslední featury. Všechno bylo otestovaný, tak merge a jde se domů. Otevíráš dveře z kanclu a volá ti projekťák, že chodí alerty z produkce. Povzdechneš si, nastartuješ kávovar a jdeš debugovat. Problém fixneš a je hotovo. Nebo ne?
Fuckupy se dějí každému, ale jejich vyřešením to nekončí. Je potřeba svoje chyby sdílet s ostatními a poučit se z nich. Není nic horšího, než když opakujeme ty samé chyby pořád dokola.
V Ackee je proto sdílíme v týmu formou DevStories, kde se nad nimi zasmějeme a něco se naučíme. Jedná se o koncept, kdy si formou příběhu sdělíme kontext, co se stalo, jak se to vyřešilo a co jsme si z toho odnesli. Ačkoli DevStories neslouží pro výsměch chybujícím kolegů, sebemrskačství je vítáno. Pojďme si dvě takové DevStories ukázat.
DevStory #1: Regex hell
Ve sprintu #20 přišel klient s požadavkem, abychom přidali podporu pro rozdělování vět ve článcích. Klient chtěl samozřejmě co nejlevnější řešení, a tak jsme po krátké diskuzi došli k návrhu, že použijeme pouze tečky jako separátor.
Bylo nám jasné, že například zkratky nebudou fungovat dobře, ale řešení jsme naimplementovali a mergnuli. Všechno fungovalo, jak mělo. Zhruba o 10 sprintů později klient přišel s požadavkem, že by chtěl změnit definici věty a přidat rozdělování dlouhých souvětí. Za konec věty se nově měla považovat skupina znaků: tečka + mezera + velké písmeno. A pokud bude mít věta více než 40 znaků a obsahuje čárku, tak čárka bude konec věty. Jak to naimplementovat? Jasně, že regexem. Vůbec nevadí, že na první pohled není vidět, co to dělá, hlavně že to je na jednu řádku, že?
/(?<=(?:\s?\p{L}\s?){41,},)(?=\s)/guŘešení naimplementováno, prošlo to přes code review, merge a jdeme na další ticket. Všechno funguje, jak má.

Objevuje se divoký alert
O rok a půl později přistává ve Slacku alert z Grafany, aplikaci dochází paměť. Jdeme debugovat – podíváme se na insights z CloudSQL a rozšíříme logy. Po deploynutí nové verze s lepšími logy jsme schopni okamžitě reprodukovat chybu. Sdíleli jsme tedy naše poznatky společně s odkazem na reprodukci chyby. Což nebyl úplně nejlepší nápad, protože lidi ze supportu na odkaz klikali a shazovali produkci dál.
Proč tedy aplikaci docházela paměť?
- Přišel request na detail článku.
- Pokud článek není v cache, je zpracován a uložen do cache (během zpracování se používal náš regex na rozdělování vět).
- Protože ale zpracování trvalo skoro minutu, klient zkusil retry.
- Zase nastal cache miss a došlo k cyklu, po kterém aplikaci došla paměť a spadla. Problém způsobil článek, který měl v sobě text, který obsahoval hodně mezer mezi písmeny. Chybu jsme opravili a vše zas jelo jako víno.
Na co si tedy dát pozor?
ReDos je skutečná zranitelnost a měli bychom si na to dávat pozor. Chyby v regulárních výrazech se velmi těžko debugují a je velmi náročné odhadnout komplexitu složitějších výrazů. Pokud je ale použijeme, je fajn vyvarovat se následujících red flagů:
- Je potřeba psát komentáře.
- Je potřeba regex rozdělit do více řádek, aby šel lépe okomentovat.
- Je potřeba vyhledávat, co dělají použité modifiery a symboly.
- Populární debugger reportuje, že je neplatný v 5 ze 7 standardů.
- Debugger regex ani nezparsuje. Některé chyby mohou trvat hodně dlouho, než se projeví – hledat změny, které byly před releasem, může být matoucí – zde se chyba projevila až po roce.
DevStory #2: A different kind of logger
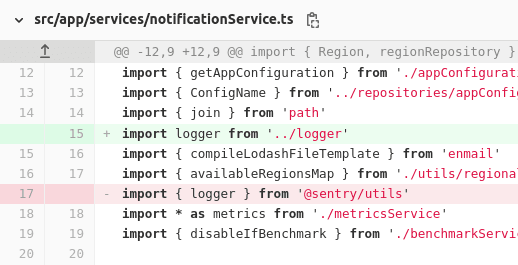
Pojďme si představit další DevStory. Na projektu máme implementovanou službu na posílání SMS a s klientem přemýšlíme nad tím, jak získat lepší statistiky o posílaných zprávách. Jako provizorní řešení jsme zatím používali aplikační logy, jenže jak v aplikaci roste počet uživatelů, narazili jsme na limit v GCP na velikost exportovaných logů. Nejdříve jsme stahovali jeden soubor, pak dva, až jsme se nakonec domluvili, že uděláme sink na logy do BigQuery. Během implementace těchto změn jsme také dělali logování posílaných SMS – používali jsme dvě SMS brány a odstraňovali duplicitní kód. Nějakou dobu po nasazení těchto změn nám píše klient, že nám úplně chybí logy ohledně posílaných SMS. Zkontrolovali jsme merge request, všechno vypadá dobře (ještě aby ne, když jsem review dělal sám). Ale logy pořád nikde. Další nápad byl zkontrolovat konfiguraci, protože pro různé části aplikace máme logger nakonfigurovaný jinak – třeba jsme tu jinou konfiguraci použili právě tady. Zapneme aplikaci v debugu a žádné logy. A v konfiguraci zřejmě problém není, logger se používá stejně jako v jiných souborech. V kódu metoda na logování je zavolána, kde tedy může být problém? Ale počkat, tenhle logger je importovaný trochu jinak než ostatní…

Povedlo se nám vyměnit logger za jiný se stejným interfacem (nejspíše kvůli autoimportu v IDE), passnout code review a ztratit důležité logy za několik dní.
Ponaučení
Chyby mohou nastat nejen ve vlastním kódu, ale i v importech. Kontrolujte při code review i importy. Pokud je potřeba logovat něco důležitého, nepoužívejte běžný logger. Je dobrý nápad vytvořit pro to specifický modul, aby se to neztratilo. Může být fajn použít lint rule na kontrolu importování interních modulů externích knihoven např. “@sentry/internal”
Sdílejte svoje fuckupy
Chyby promlčením nezmizí. DevStorky si prezentujeme v týmu na týdenních mítincích. Jsou to vždycky nejzajímavější témata, protože to odlehčí atmosféru, je to zábavné (ideální příležitost k tomu vytvořit nějaké meme) a vždycky to vede k ponaučení nebo diskuzi, jak se problému příště vyhnout. Fuckupy totiž často nejsou problémy jednotlivců, ale špatně nastavených procesů. Co publikovatelného se povedlo vám? Svěřte se nám třeba na Twitteru, anebo přijďte pokecat na další Ackee meets, rádi se poučíme.





